@misc{doubleml,
title = {DoubleML},
author = {Bach and Chernozhukov and Kurz and Spindler},
howpublished = {\url{https://docs.doubleml.org/}},
note = {Software / documentation}
}Turn debiased CATEs into a rule: fit a shallow, readable decision tree that maximises the doubly-robust policy value.
Input · what goes in
Outcome Y, binary treatment D, covariates X you'd target on (and a cost, implicitly).
Show data format & exampleHide example
Format — one row per unit: y, d, targeting covariates X.
y d x1 x2
1.2 1 0.4 -1.1
-0.3 0 -0.1 0.6
Pipeline · the recipe ⑂ has parallel branches
↑ Click any step in the diagram to read its logic, code, assumptions & discussion.
Orthogonal scores from an IRM
The core estimate — where the causal quantity itself is computed.
Cross-fitted doubly-robust scores Γ — the reward signal for each unit.
dml_irm = dml.DoubleMLIRM(dml_data, ml_g, ml_m).fit()
- No comments on this step yet — be the first.
Log in to comment on this step.
Fit a depth-limited policy tree
Heterogeneity — who is affected, and by how much, not just on average.
Choose the rule that maximises the average doubly-robust value over a shallow tree class.
tree = dml_irm.policy_tree(features=X, depth=2)
tree.plot_tree()
- No comments on this step yet — be the first.
Log in to comment on this step.
Read the tree & its value
Reporting — turn the numbers into a figure or table a reader can act on.
Plot the rule and report its value vs treat-all / treat-none.
# value(pi) = mean of DR scores under the learned assignment
- No comments on this step yet — be the first.
Log in to comment on this step.
Output · what you get 2 figures
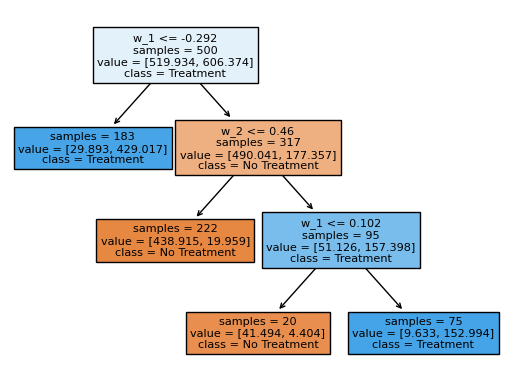
Figures reproduced from DoubleML — Bach, Chernozhukov, Kurz & Spindler — unofficial community showcase; all credit to the original authors.
⚠️ Unofficial community showcase of a DoubleML example. Not affiliated with the authors; figures are from the public documentation. All credit to Bach, Chernozhukov, Kurz & Spindler.
Turn debiased CATEs into a rule: fit a shallow, readable decision tree that maximises the doubly-robust policy value.
Discussion (0)
Log in to join the discussion.