@misc{grf,
title = {grf},
author = {Athey and Tibshirani and Wager},
howpublished = {\url{https://grf-labs.github.io/grf/}},
note = {Software / documentation}
}Evaluate how well a CATE estimate prioritizes treatment: TOC curve, AUTOC and Qini with confidence intervals.
v2.6.1tag
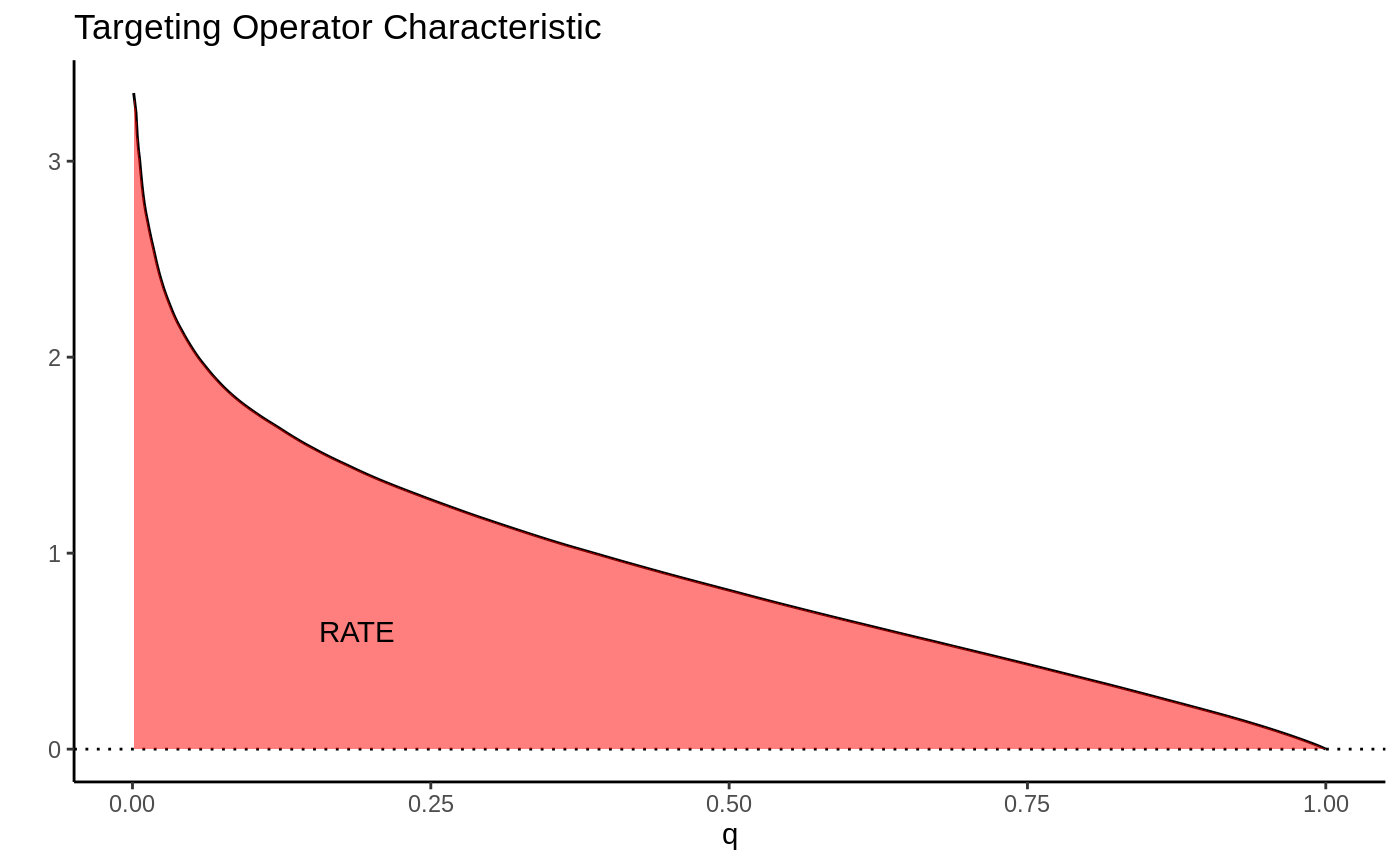
Figure: TOC curve with the AUTOC area shaded. Source — grf-labs docs.
⚠️ Unofficial community write-up of a method from grf-labs/grf (pinned at
v2.6.1). Not affiliated with the grf-labs authors — this summarizes the public documentation for demonstration. All credit & copyright belong to the original authors (Athey, Tibshirani, Wager, et al.).
What it does
Answers 'is my CATE model actually useful for targeting?' Builds the TOC (Targeting Operator Characteristic) curve and summarizes it as AUTOC or Qini, with confidence intervals from a held-out evaluation forest.
rate <- rank_average_treatment_effect(eval.forest, priorities = tau.hat)
plot(rate) # TOC curve
rate$estimate / rate$std.err # is targeting better than treating everyone?
Why it matters
A model can have a great AUC and still be useless for prioritization. RATE tests the thing you actually care about. (Yadlowsky et al., JASA 2025.)
Used in these workflows (3)
-
Cross-fold validation of heterogeneity
K-fold cross-fitted CATEs → RATE on out-of-fold priorities → honest verdict on heterogeneity strength.
-
Assessing heterogeneity with RATE (AUTOC & Qini)
Causal forest → train/eval split → RATE with both AUTOC and Qini → TOC plot.
-
Heterogeneous treatment effects with a causal forest (GRF recipe)
The full GRF HTE playbook: cross-fit nuisances → causal forest → calibration → AIPW ATE → BLP → RATE → policy.
THE method everyone skips and shouldn't. A high AUC CATE model can have an AUTOC indistinguishable from zero — i.e. useless for prioritization. Test the thing you actually deploy.
We caught a 'great' model that was worthless for targeting exactly this way. Saved a campaign.
AUTOC vs Qini choice matters more than people think: AUTOC for concentrated benefit, Qini when you treat a big fraction. Pick before you peek.